A novel approach to learn robotic dexterity
A brief introduction #
Complex robotic movement is an integral component of the multitude of tasks that robots are expected to perform. Robotic movement is essential in the automation of manual labor, so improvements in robotic movement have a large impact on industrial efficiency.
Robotic control has been accomplished by two main modes:
- Classical controllers
- Reinforcement learning controllers
Classical controllers usually require precomputed models of the environment in order to function, but in many cases, models of the environment cannot be readily provided. Reinforcement learning controllers do not require models, instead, they learn the environment through experience. Reinforcement learning controllers are inefficient in training since the state action reward space is usually very large for a RL agent to explore.
Objective #
The objective of my project was design an algorithm for a robotic controller that converges in a shorter allotment of time and better efficiency than Twin Delayed Deep Deterministic Policy (TD3) and Soft-Actor Critic (SAC).
Our algorithm shouldn’t require a model of the environment, it should solve the issue of sample efficiency, and it achieve similar or superior performance to the above state-of-the-art algorithms.
Design #
In order to make a more sample efficient model-based controller, we develop a method where we don’t learn the model directly, rather, we implicitly define the model by embedding it into higher dimensional eculidean space using a neural network to represent the mapping. We also train a network to transform actions to a new coordinate system using a neural network and train so that both mappings are consistent with a linear transition function between states with a quadratic reward. This allowes us to use a Linear-Quadratic Regulator to plan the actions for the new system.
My team and I used FetchReach-v1 from the OpenAI Gym Environment as our test. We implemented both TD3 and SAC and ran it with FetchReach-v1 to get our controls. We then ran our novel algoirhtm on FetchReach-v1 and analyzed the results.
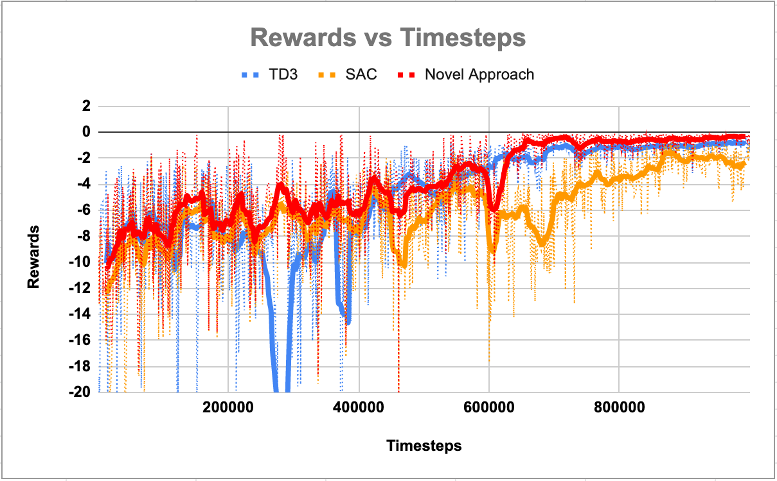
We found a notable improvement in convergence times over TD3 and SAC. Although all algorithms converged at about the same timesteps, our algorithm was much less computationally intensive and finished convereging at an earlier on-the-wall-clock time.
An official paper may be published later this year.